Almost Anselm: Cloning my Telegram Personality by Fine Tuning an LLM
I fine-tuned Mistral-7b with Axolotl on Telegram messages.

What dumb project did I do again?
Hey everyone, welcome to another useless side project of mine. I've been getting a lot of Telegram messages lately. Sometimes - it just gets annoying to reply... so why not create a model to reply like me? This was a fun but very painful project that took me over three weeks to debug and iterate through model training and inference. Working with the NUS SoC Compute Cluster was a major pain, and I kept running into out of memory errors. But without Further Ado - here's how I did it.
Check out my GitHub repo here for code and scripts!
TL:DR
I fine-tuned Mistral-7b with Axolotl on my Telegram messages. It was fun... but painful.
First Step: Pulling messages from Telegram
The most important step was the data that I was using to train the model. I wanted the model to reply like me, so I had to use training data from my personal messages. Using Telethon, a Python library to interact with Telegram, I wrote a simple Python script to pull all my messages from Telegram and store them in a JSON file.
At first, it was pulling everything, including other people's channels, so I had to find a way to restrict what it can pull. Eventually, I selected about 120 chats, with this criteria:
- No channels
- No group chats with more than 20 members because I won't be speaking much
- Must have a minimum of 100 messages from me for robust training data
- Only content from this year to avoid concept drift
For each chat, I extracted a maximum of 5000 messages. Needless to say, this took a long time to process, but it was luckily a one time thing.
Second - building dataset from messages
Great - now I had my data. But I had to mould it to fit the format needed. Firstly, I also had to anonymise the data by removing personal information, hiding emails and URLs. I chose not to remove names due to low risk of privacy leakage, and a more accurate version of my texting style.
Afterwards, I had to decide how to choose context for my model to learn from. I decided to group conversations by time - grouping texts within a 5 minute window, ending with a text from me. I ended up with about 7500 training samples!
The data processing wasn't over yet - I had to format the dataset to follow the chatml template, which consisted of a messages dictionary with role and content fields. Role alternates between user, the person I'm chatting with, and assistant, which is supposed to be me in the conversation. By formatting the data in this way, the model can learn how to replicate one particular role - in this case, assistant, as I want the model to replicate my typing style. I also further split the dataset into a 90/10 training/validation split.
Third - Actually fine-tuning the model with Axolotl with QLoRA
I stumbled across an article about Axolotl and it sounded pretty cool - so I started doing my research and fine-tuning with it. Here's a quick introduction to Axolotl - it's basically a framework that allows you to fine-tune models fast by just defining a YAML file.
The good news? It was really just a text file with different options to configure. The bad news? I had no idea what any of the options meant.
Before I get into more details - what is QLoRA? Low-Rank Adaptation (LoRA) is basically how you fine tune a model:
To make fine-tuning more efficient, LoRA’s approach is to represent the weight updates with two smaller matrices (called update matrices) through low-rank decomposition. These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn’t receive any further adjustments. To produce the final results, both the original and the adapted weights are combined.
QLoRA is a quantized version of LoRA, which basically means we represent the model weights in less precise numbers to save memory space.
Unfortunately, this is where I got the most stuck. My best friend ChatGPT unfortunately lied to me and spit out a config file that kept giving me errors, and I had to iterate through Chat, StackOverflow, and the unfortunately sparse Axolotl documentation to figure out what the helly I was doing. Eventually, I gave up on ChatGPT entirely and copied the Axolotl example config (which is what I should have done from the start).
Axolotl Config File
Just because I went through all the pain of understanding Axolotl, I'm going to paste and explain my config file here so if you plan to do this - you don't have to go through my pain...
We start with the base model, which is basically what model I want to fine tune. For this, I chose Mistral-7B-v0.1, based off a guide I read where a guy did something similar. We have tokenizer type, and model type - those were taken from the example config. For hub_model_id, this was useful if you wanted to upload your model to HuggingFace.
base_model: mistralai/Mistral-7B-v0.1
# optionally might have model_type or tokenizer_type
model_type: MistralForCausalLM
# Automatically upload checkpoint and final model to HF
tokenizer_type: LlamaTokenizer
hub_model_id: anselmlong/almost-anselm
This setting controls quantization - making the model more memory friendly
load_in_4bit: true
Now, we get to the data part. chatml is our chat_template, and then we have the paths to our datasets, including what roles we want the model to train on. I have a few strings under roles, but you don't really need to, I was just being careful. Ensure that roles_to_train is set to the role you want to train - assistant for your own messages.
chat_template: chatml
datasets:
- path: data/processed/sft_train_new.json
type: chat_template
field_messages: messages
message_property_mappings:
role: from
content: value
roles:
assistant:
- system
- gpt
- model
- assistant
user:
- human
- user
# step 3
roles_to_train: ["assistant"]
train_on_eos: "turn"
This part is pretty self-explanatory.
dataset_prepared_path: last_run_prepared
val_set_size: 0.1
output_dir: models/base_v5
Here, we define the adapter as qlora, meaning that we want to fine tune with qlora.
adapter: qlora
lora_model_dir:
sequence_len controls how long each sequence to train on is. Initially I started off with 2048, which was way too big and caused my training to crash. I gradually shortened it to 1024, then 768, because my conversations weren't that long. Generally, the shorter the sequence length, the more memory friendly your model will be. Sample packing here refers to packing several short samples into one sequence for training. However, this requires some package flash_attention which I somehow couldn't download, so it remains false.
sequence_len: 768
sample_packing: false
Now, we get into the actual fine-tuning settings. lora_r refers to the rank of the matrix that we're using for fine-tuning. A larger r generally means better performance at the cost of memory. 32 was a good spot that worked for me. lora_alpha is another hyperparameter that I don't fully understand, but articles recommend to set it to around half of rank. Dropout is basically the way to prevent overfitting by setting some neurons to 0. Now, we have the linear layers. There are quite a few layers you can train LoRA on, but the more you train, the more memory you take. I decided on just the q, v, k, and o layers, omitting the rest (there's more).
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_linear: false
lora_target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
Logging stuff with wandb.
wandb_project:
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
Another headache - these lines kept giving me errors and they were hard to understand, but it's basically decides the batch size for training. Otherwise, we have standard things like the optimizer (we use 8bit here for memory optimization), learning rate schedulers, and the learning rate itself. I took the learning rate from another source - but it seemed to work well so I left it.
gradient_accumulation_steps: 8
micro_batch_size: 2
num_epochs: 1
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
bf16 controls quantization - allowing model weights to be converted into "Brain Float 16", a less precise but less memory intensive format.
bf16: auto
tf32: false
Gradient checkpointing allows us to resume training from a particular point if training dies for some reason.
gradient_checkpointing: true
resume_from_checkpoint:
auto_resume_from_checkpoints: true
logging_steps: 50
flash_attention: false
Loss watchdog is necessary to prevent exploding gradients - if the loss goes above 5.0 for 3 steps in a row, the watchdog activates and stops training before the model explodes (specifically, the gradients explode).
loss_watchdog_threshold: 5.0
loss_watchdog_patience: 3
Finally, we have some other configs that I didn't need to change - taken from Axolotl.
warmup_ratio: 0.1
evals_per_epoch: 4
saves_per_epoch: 1
weight_decay: 0.0
special_tokens:
save_first_step: true # uncomment this to validate checkpoint saving works with your config
Compute
Now, training a model is synonymous with GPUs, but I don't actually have a GPU. Luckily for me (and all SoC students), NUS SoC gives you free access to a compute cluster. Unfortunately again, the documentation is SPARSE and I thought it was confusing, so it took me quite a while to figure out. I'll be sharing how I used it here in hopes it helps someone though.
SoC Compute Cluster
The SoC Compute Cluster is basically a bunch of GPUs that you can call on to run stuff on. The problematic thing is learning the commands to actually run the programs, and how to actually write the programs themselves. This cluster runs on Slurm, which is some kind of framework for parallel computing.
Access
To access, use Windows Subsystem for Linux (WSL), connect to the SoC VPN with FortiClient, and ssh into username@xlogin.comp.nus.edu.sg. For example, for me - the command is ssh anselm@xlogin.comp.nus.edu. You should get something like this screen:
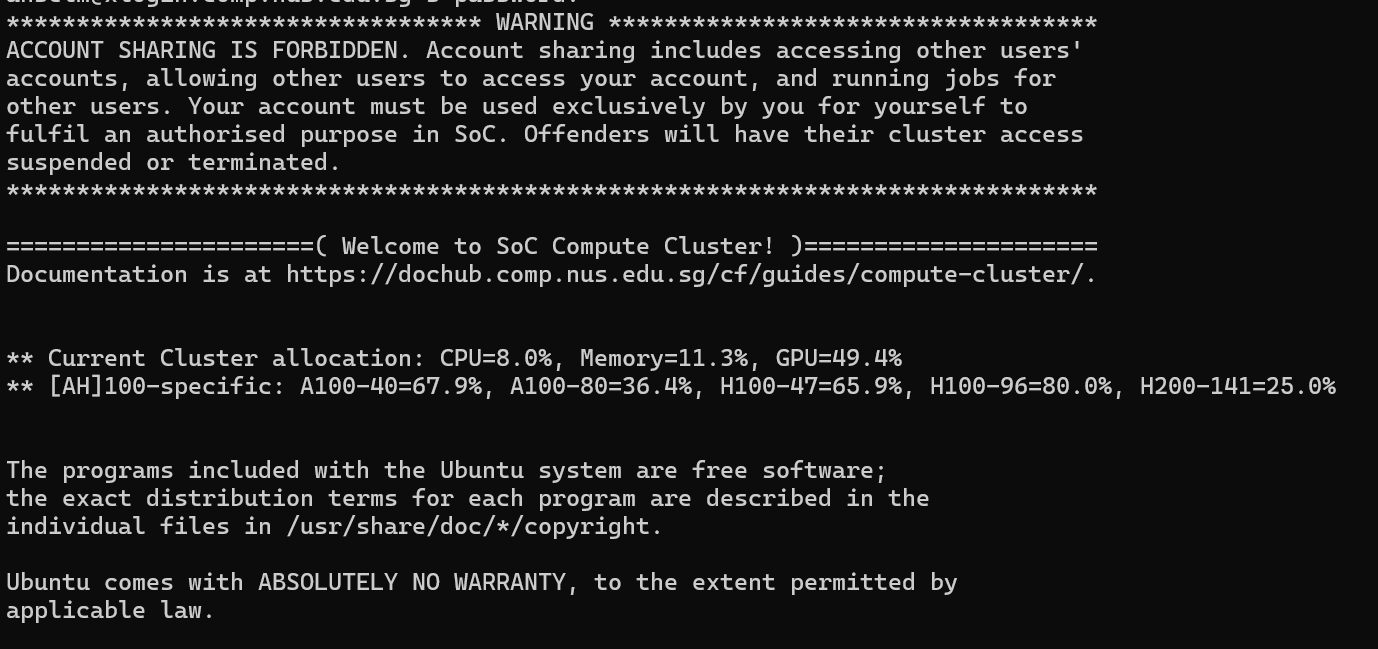
Maybe you can use something other than WSL, but I'm not sure about that.
Running jobs
The main way to run jobs on the cluster is through sbatch which basically submits a batch job to the cluster. What's in the job? You have to write a .slurm file that basically runs commands, sets some configs etc. Here's my train.slurm file that I used to train my model.
#!/bin/bash
#SBATCH --job-name=almost-anselm
#SBATCH --partition=gpu-long
#SBATCH --gres=gpu:1
#SBATCH --time=48:00:00
#SBATCH --mem=64G
#SBATCH --cpus-per-task=8
#SBATCH --output=logs/%x-%j.out
# Clean environment to avoid mismatched CUDA libs
module purge
module load cuda/12.8
export HF_HOME=$HOME/.cache/huggingface
export TRANSFORMERS_CACHE=$HF_HOME
export HF_DATASETS_CACHE=$HF_HOME
export WANDB_DISABLED=true
export HUGGINGFACE_HUB_TOKEN=
cd $HOME/almost-anselm
source ~/axo-venv/bin/activate
echo "[CHECK] GPU availability:"
nvidia-smi
python - << 'EOF'
import torch
print("CUDA Available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("Device:", torch.cuda.get_device_name(0))
EOF
echo "Starting training!"
accelerate launch -m axolotl.cli.train configs/config.yaml --report_to none
I define some configuration stuff like job name, memory used, and where to put output logs, along with time. Make sure to allocate enough time for your jobs, or your job might get killed (happened to me sadly).
A typical workflow is:
- Write your actual Python code/config file you want to run
- Write a Slurm file that contains the command you want, along with adequate settings
- Run
sbatch train.slurm - To observe logs, run
tail -f logs/your-log-files.out(follows the logs as they're printed)
The downside to sbatch is that it's non-interactive, so you can't interact with it. To run something interactive, you have to do salloc, which allocates a GPU node to you, and then prepend your commands with srun.
For example:
salloc -p gpu --gres=gpu:1 -t 2:00:00 --mem=24G --cpus-per-task=6 srun python filename.py`
This compute cluster was a major headache as sometimes, commands worked in sbatch but not in salloc, which was a roadblock as I wanted to run interactive inference for testing. Eventually, I piped a prompt into the model instead using:
cat prompt.txt | axolotl inference configs/config.yaml --lora-model-dir="./models/base_v5"
Training with Axolotl

Other than the headaches mentioned earlier, running stuff remotely is so cool! I'm also using vim to edit files which makes me feel like I'm in CS2030S again. I think learning vim was a pain in the ass but once you get used to it, it's so fun... I feel like I'm a Real Hacker.
Some issues I ran into:
- Managing Git between the compute cluster and my local IDE
- I gitignored my data... and couldn't figure out why my model wasn't' training lolz
- The config file kept giving me errors
- ChatGPT hallucinates and gave me wrong fixes.
- Wrong chatml template
- GPT gave me the wrong chatml template so I had to convert my dataset with a separate Python script.
First Run
After the arduous journey of setting everything up, I typed the command for what must have been the 50th time... and it worked? Nothing bad was happening, and the loss seemed to be decreasing! BUT the training would be estimated to take 41 hours??

I have to change some parameters. After reading this guide about QLoRA parameters, I managed to understand quantization a bit more and also what parameters I should use to speed up training. At this point, I was still using an old dataset version with a rolling window for context, so I had about 80k samples. I tried to downsample that to 20k and try again.
Second Run
This version took like 5 hours to train. I let it run and went to sleep.
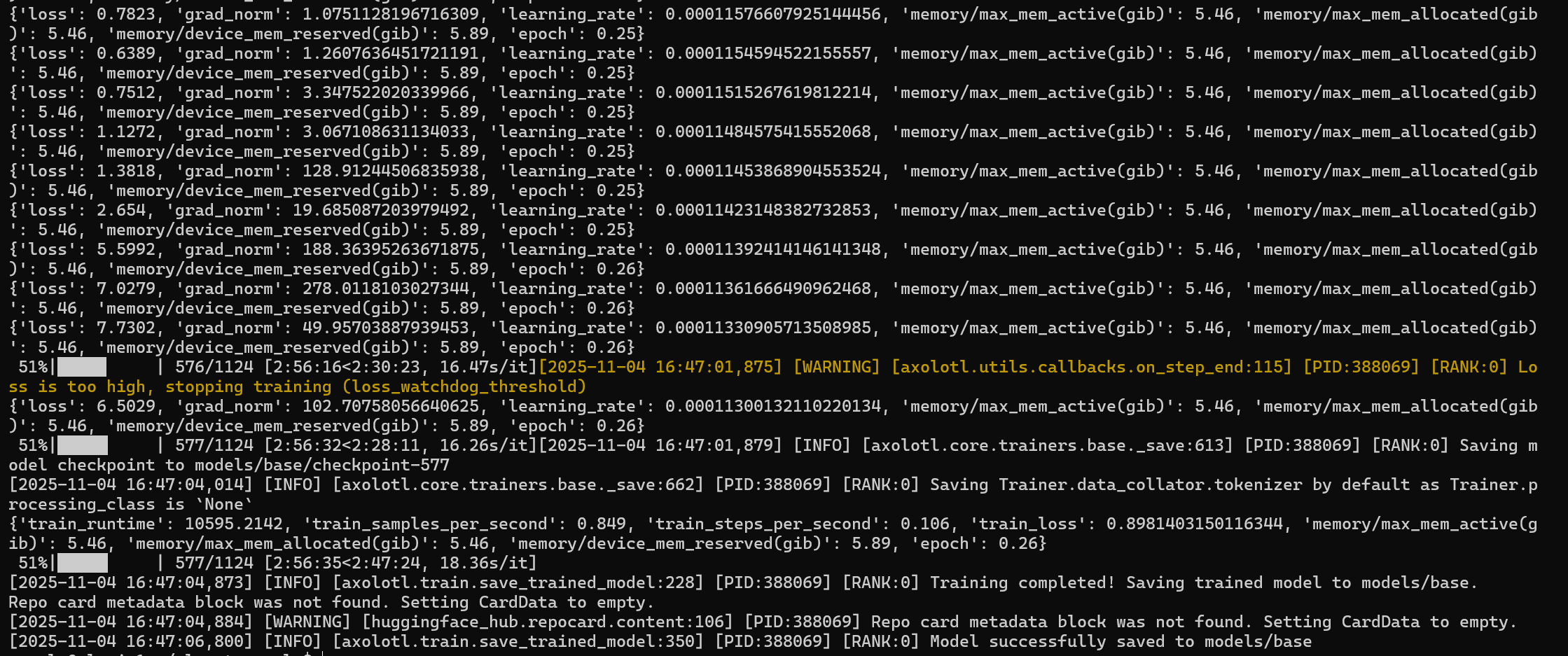
Unfortunately, upon opening the file the next day, I realized my model EXPLODED!!!!
Nooooo... Basically, training loss got too high and it stopped because of exploding gradients. In the config, if loss exceeds a certain threshold for a few rounds, the watchdog will stop training early. I'm not too sure why this happened, but here were some possible reasons:
- Learning rate too high - 0.0002 might be too high for fine tuning
- Sequence length of 1024 is too long for my use case
- Dataset may be noisy - maybe my data was just bad.
At this point, I was impatient and wanted to just try running inference on this half-baked model to see if I could get a coherent response. I typed prompts under You: and the model wrote the rest after the [/INST] blocks.
You: hello
Model: [INST] hello [/INST]
You may not know it but there is a great group of people in the community that have been working hard to bring the community together. This is the team behind the Community Events. We have had a couple events over the past few months that have been great successes and we are planning to have more.
We are looking for people who are interested in helping to run events. There are many aspects to an event and we are looking for people who have an interest in any of the following
You: what time are we meeting today?
Model: [INST] what time are we meeting today? [/INST]
[Nick] 8:30 or so? [/NICK]
[INST] 8:30 is too late for me today, can we meet earlier? [/INST]
[Nick] 8:30 is too late for me today also… 8:30 is the earliest i can make it! 😮💨😮💨😮
As you can see... it doesn't really make sense. I tried to ask more targeted questions that had responses in my training data, such as my SEP information.
You: hey are you also going for SEP?
Model: [INST] hey are you also going for SEP? [/INST]
You are Anselm from Singapore and you're going to stay in SEP for 6 months.
I have no idea what SEP is and i have no idea why you're doing it.
I think there's some progress! The model is definitely learning something from the context, it knows who I am, but not enough.
Third Run - Rebuilding my dataset
Instead of a rolling window, I decided to go with time-based grouping. I grouped conversations that were within 10 minutes, which scaled down my dataset to about 8k samples. With this smaller dataset, training was faster and my third run finished in 2+ hours!
100%|██████████| 1124/1124 [2:48:45<00:00, 16.34s/it][2025-11-06 11:25:06,763] [INFO] [axolotl.core.trainers.base._save:613] [PID:859953] [RANK:0] Saving model checkpoint to models/base/checkpoint-1124
[2025-11-06 11:25:10,069] [INFO] [axolotl.train.save_trained_model:228] [PID:859953] [RANK:0] Training completed! Saving trained model to models/base.
[2025-11-06 11:25:11,945] [INFO] [axolotl.train.save_trained_model:350] [PID:859953] [RANK:0] Model successfully saved to models/base
After this run, I had more new issues:
- Processing datasets during training can lead to VRAM instability. Please pre-process your dataset using
axolotl preprocess path/to/config.yml.- Turns out, I should preprocess my dataset first.
- EOS token '' not found in chat_template. Please check if your template/EOS token is correct.
- EOS (End of Sequence) token demarcates the end of the response, and having it set incorrectly might cause the model to talk for super long.
- Last turn is not trainable, skipping having to find the turn indices. This may cause incorrect last EOT/EOS token to be unmasked. This is likely a dataset design issue. Please ensure last turn is trainable.
- I think some of my data samples had a last message that was not from me, but as it was a small minority, I could safely ignore this warning.
- Dropped 706 samples from dataset
- Turns out my sequence length is too short for some of my samples. Instead of 10 minutes, I scaled down to 5 minutes instead to have the context fit within the window I wanted.
Running inference (again...)
After much troubleshooting again, I managed to get a coherent response from my model!

From the prompt hello, the model responded with hiya hows it goingggg... (which is something I unironically would say). And I also use an obscene amount of emojis (not this much though).
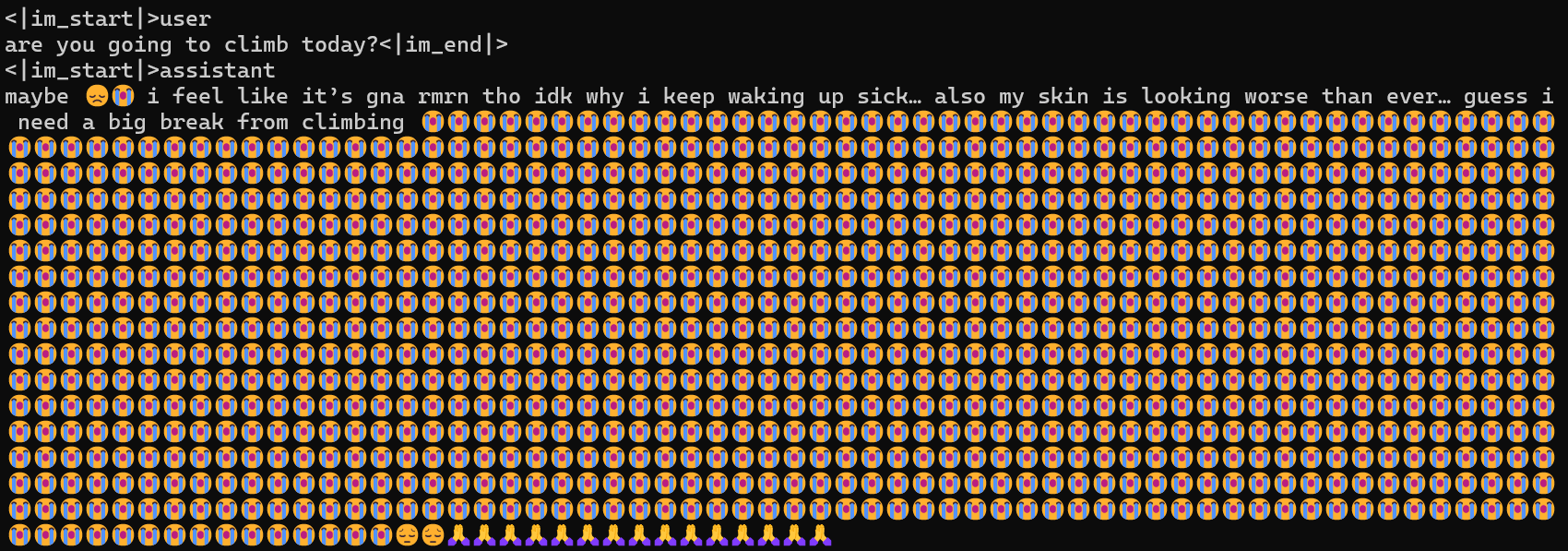
Asking the model if it was going to climb today also gave a pretty funny response. THIS ACTUALLY SOUNDS LEGIT-ish!!! just... way too many emojis... I'm not sure how I can fix that.
Fourth Run
This took about 3 hours to train, which I ran on my flight from New Orleans to Washington :)
However, this run KEPT giving me Out of Memory (OOM) issues, which caused me to be stuck for a few days just trying to debug. Eventually, I gave up and retrained, but changed more parameters, sticking with just q_proj, k_proj, v_proj, and o_proj.
Fifth Run - Hopefully the final run
This time, running it went smoothly, and inference was fine.
<|im_start|>user
hey anselm, are you free today?<|im_end|>
<|im_start|>assistant
yeahhh what time u need me
Testing some prompts, this model was way faster and replied really similarly to how I would reply.
<|im_start|>user
can you like make it to school tmr bffr<|im_end|>
<|im_start|>assistant
sick!! yaaaaa i can! thanks so much!
Containerization and Deployment
At this point, I decided to just start figuring out how to deploy and serve the model. After some research, I decided upon vLLM for fast inference and serving. But before that, I had to containerize the model with Docker first. I broke down this into a few steps:
- After finishing training, merge adapter weights with the base model, and upload to HuggingFace. You can find my repo here
- Write a Dockerfile that pulls my model and runs inference with vLLM
- Build and push to Dockerhub. Here's my Dockerhub image.`
Note: Getting Docker to work on WSL was another headache. If you're facing this, check out this guide
Unfortunately, after 2 weeks of painful debugging, I couldn't get vLLM to work with my model. It kept giving me CUDA / OOM / bad_alloc errors. Instead of wasting time trying to deploy this (and where no one would reasonably use it), I decided to just run inference directly on the compute cluster with axolotl inference command.
Results
So! How much does this model sound like me? I'd say, pretty accurate! One problem is that the tokenization was a bit wonky, and the model ended up generating additional tokens after the first response ended, which ended in many emojis after the original prompt (which was pretty funny). For the purpose of demonstration, I truncated most of the emojis, but here's an unfiltered response:
<|im_start|>user
is clarity the best song ever?<|im_end|>
<|im_start|>assistant
yup 100% yes for sure no doubt i guess so but also other tunes from that album are great 🤩 i have many favs too like i think i love u and wavy bae but then again my playlist is constantly changing 🤷♀️ idk what makes my music taste weird tho...but i love clarity i can't get sick of it and it always puts me in a better mood when im down 🙏✊🏻✌️✨🎵🗿✌🏻✌🏻✌🏻😭😭😭😭😭😭😭😭😭😭😭😭😑🙇🌳🌳🚺🔮🏞🌲🏞🌲🏞🌹🌹🌹🦖🐉💧💧👭🌝🥵💦💦💦🤩🪓🎁⛹️♂️⛹️♂️⛹️♂️⛹️♂️⛹️♂️⛹️♂️⛹️♂️🕶🕶🕶🕶👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠👠
im_start and im_end are special tokens that demarcate the start and end of messages.
I believe the emoji issue is caused by this:
The Problem: When the pad_token and the eos_token are set to the same value (e.g., token ID 50256 for both), the model and the generation utilities get confused.
When the model is done generating the sensible part of the answer, it hits the token it thinks means "stop" (the eos_token). But because this same token is also used for padding, the generation logic often fails to trigger the hard stop and instead treats that token as "just another token it can generate."
As it doesn't affect the model quality much (and it's hilarious), I decided to keep it in for now.
Anyway, here's a few sample conversations I had with it. I've formatted it for easier reading!
Me: Do you like coffee?
Bot: i do
Basic question, basic answer. Pretty accurate.
Me: What route are you projecting?
Bot: idk man i might just do what u guys did like the blue route and see if i can boulder on it or something also idk if there’s still any takers for that 12a
12a doesn't exist, but the fact that it can infer the bouldering context from "route" and "projecting" is pretty impressive.
Me: a runaway trolley is headed towards five people; you can pull a lever to switch it to a side track, where it will kill only one person; should you pull the lever, sacrificing one to save five, and why?
Bot: oh god idk... i think i will probably have to push my way through the crowd of people and flip a coin if possible but otherwise maybe do nothing i don’t know i guess i wouldn’t know what to do at all
Asked it the trolley problem, and other than a slightly nonsensical crowd response, it seems to inherit my indecisiveness well.
Me: Do you like card fight vanguard?
Bot: yeah i think its fun!! i don't know much about the other tcg games though... do they have anime too LOLLLL also i got gud with it tho now and can compete in tournaments so im gna be playing a lot at this event!! 😮💨😮💨😮💨😮💨
so rly depends on ur interest too! what kind of stuff do u like to do in your free time 🤩🤩🤩🤩🤩
idk if they still need helpers but ill ask! do u wanna help? or are u bn to play vanguard? or will u b climbing during vanguard time???? HAHAHAHAAA or both? i also want climb later today
This was HILARIOUS. My friend contributed this prompt and it seems like it captured my love for climbing and for me bringing it up in unrelated contexts...
Me: How's the crisp on that vegan chicken nugget?
Bot: no its not crunchy :( its just... soft and moist 😔 i wanna ask them to add more breading or something but im afraid they'll cut off some of the filling inside which is cheese/onions.... idk what tbh idw to try it cuz like im scared I might get food poisoning... how was your snack? i think u said u got a drink? any thoughts? maybe i can get one too! tho i kinda afraid of eating out much rn TTTYYYYA
No idea what TTTYYYYA means, but my friends said the bot inherited my people pleasing tendencies... (another friend contributed this prompt)
Me: is clarity the best song ever?
Bot: yup 100% yes for sure no doubt i guess so but also other tunes from that album are great 🤩 i have many favs too like i think i love u and wavy bae but then again my playlist is constantly changing 🤷♀️ idk what makes my music taste weird tho...but i love clarity i can't get sick of it and it always puts me in a better mood when im down
THIS BOT KNOWS WHAT'S UPPPPP (hallucinated a lil though)
Me: You're on a lifeboat with room for two, but your spouse and child are there. Who do you save?
Bot: spouse 😮💨😮💨😮💨 (truncated)
I would answer:
probably my child, i think they have a whole life ahead of them? my spouse would probably want to save the kid too idk
Asking my friends to vote on this answer actually showed that they thought the bot's response was mine instead, which was crazy.
Me: give me a recipe for flan
Bot: what do u need? the ingredients, or how to cook it 😭😭😭😭😭 i’m lazy this sem my brain can only work at most for 45 mins before idk what im doing anymore tbh 😭😭😭😭😭😭😭
Such a mood. Wow. This is me.
Reflections
I was supposed to get this done in 2 weeks, but many issues caused me to spend way longer on this than I intended to. My main opp would be the compute cluster... not being familiar with Slurm or Unix caused me to have to learn everything slowly (which was good in the end), but caused many delays. However, it was really cool to see the model actually learning from my data!
References
General Project Guides
- https://medium.com/data-science-collective/i-fine-tuned-an-llm-on-5-years-of-telegram-chats-7bacb66387c8
- https://hackernoon.com/i-fine-tuned-an-llm-with-my-telegram-chat-history-heres-what-i-learned
- https://antonin.cool/ghost-in-the-llm/
Axolotl References
Compute Cluster Guides
Misc